В данной статье будет описано создание сборщика писем на PHP. Если в один прекрасный день у вас возникла необходимость забирать письма с почтового (почтовых) ящиков и куда-то складывать (скорее всего, в базу данных), то добро пожаловать. Очень надеюсь, что статья вам пригодиться и облегчит жизнь. В третьей части статьи будут приложены все необходимые коды. И так поехали...
Сначала определимся с требованиями:
1) Реализация на
PHP
2) Чтение писем по протоколу
IMAP
3) Запись содержимого писем в базу
MySQL
4) Сохранение вложений к письмам в файловой системе
5) Будет реализовано два скрипта: первый проверяет новые письма, а второй закачивает письма
6) Будет таблица, содержащая список почтовых ящик, с которых собираются письма
7) Также будет сохраняться информация о том: от кого письмо, кому письмо, кому переадресовано, кто в копии и кто в скрытой копии
Почему именно такой выбор?
Письма можно читать с почтового сервера по протоколам IMAP и POP3.
Реализация сборщика будет построена с использованием протокола IMAP, т.к. он имеет ряд преимуществ. Не знаю как в реализациях POP3 на других языках, но в PHP мне не удалось получить UID письма, можно получить только порядковый номер письма среди новых. Также минусом при использовании POP3 является то, что письма нужно считывать с первого раза. А у нас будет другая реализация: письма сперва проверяются, а только потом закачиваются, что возможно благодаря IMAP.
Вложения к письмам будем хранить в файловой системе, а в базе данных будут храниться только пути к этим файлам (хотя вам никто не запрещает записывать файлы в базу данных)
ПРОЕКТИРОВАНИЕ ТАБЛИЦ
Таблица почтовых ящиков
Создадим в MySQL новую базу данных
mail_collector с кодировкой UTF-8 по умолчанию:
CREATE DATABASE mail_collector DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
Создадим таблицу
mailboxes, которая будет хранить необходимую информацию для подключения к почтовому ящику.
CREATE TABLE mailboxes
(
id int PRIMARY KEY NOT NULL AUTO_INCREMENT,
email varchar(50) NOT NULL,
password varchar(50) NOT NULL,
host varchar(50) NOT NULL,
port varchar(50) NOT NULL,
is_ssl bit NOT NULL,
is_deleted bit NOT NULL,
last_message_uid int NOT NULL
);
Назначение полей:
email - почтовый ящик
password - пароль от ящика
host - адрес почтового сервера. Например, imap.gmail.com или 173.194.71.108
port - порт, по которому работает почтовый сервер
is_ssl - если флаг установлен, то подключение будет по SSL
is_deleted - если флаг установлен, то почтовый ящик считается удаленным и не участвует в сборке писем
last_message_uid - поле используется для хранения UID последнего считанного сообщения
Заполним таблицу
mailboxes данными трех почтовых ящиков, созданных на разных почтовых серверах: gmail, yandex и mail.ru. В качестве примера к почтовым ящикам на
gmail и
yandex будем подключаться через SSL, а на
mail.ru - без SSL.
INSERT INTO mailboxes(email,password,host,port,is_ssl,is_deleted) VALUES
('mail.collector.kz@gmail.com','mail.collector','imap.gmail.com','993',1,0,0),
('mail.collector.kz@mail.ru','mail.collector','imap.mail.ru','143',0,0,0),
('mail.collector.kz@yandex.ru','mail.collector','imap.yandex.ru','993',1,0,0)
Таблица сообщений
Создадим таблицу
messages для хранения сообщений:
CREATE TABLE messages
(
id int PRIMARY KEY NOT NULL AUTO_INCREMENT,
mailbox_id int NOT NULL,
uid int NOT NULL,
subject varchar(255),
body_text text,
body_html text,
attachment_count int,
header text,
message_date datetime,
create_date datetime NOT NULL,
modify_date datetime,
is_ready bit NOT NULL
);
Так же создадим внешний ключ на таблицу mailboxes:
ALTER TABLE messages ADD CONSTRAINT fk_messages_user_id
FOREIGN KEY (mailbox_id) REFERENCES mailboxes(id);
Назначение полей:
mailbox_id - ссылка на почтовый ящик, к которому относится письмо
uid - уникальный номер письма в почтовом ящике
subject - тема письма
body_text и
body_html - письмо храниться на сервере в виде обычного текста и html-версии
attachment_count - кол-во вложений письма
header - технический заголовок письма
message_date - дата письма
create_date - дата создания записи
modify_date - дата изменения записи
is_ready - письмо полностью загружено
Таблица адресов
Создадим таблицу
addresses для хранения адресов: адрес отправителя, адреса получателей, адреса получателей скрытой копии и т.д.
CREATE TABLE addresses
(
id int PRIMARY KEY NOT NULL AUTO_INCREMENT,
message_id int NOT NULL,
type varchar(10) NOT NULL,
email varchar(50) NOT NULL
);
И создадим внешний ключ для связи с таблицей
messages:
ALTER TABLE addresses ADD CONSTRAINT fk_addresses_message_id
FOREIGN KEY (message_id) REFERENCES messages(id);
Назначение полей:
message_id - ссылка на сообщение, к которому относится данный адрес
type - тип адресата: "from" (отправитель), "to"(получатель), "cc" (скрытая копия) и т.д.
email - адрес электронной почты
Таблица вложений
Создадим таблицу
attachments для хранения информации о файлах прикрепленных к письму:
CREATE TABLE attachments
(
id int PRIMARY KEY NOT NULL AUTO_INCREMENT,
message_id int NOT NULL,
file_name varchar(255) NOT NULL,
mime_type varchar(255) NOT NULL,
file_size int NOT NULL,
location varchar(255) NOT NULL
);
Создадим внешний ключ для связи с таблицей
messages:
ALTER TABLE attachments ADD CONSTRAINT fk_attachments_message_id
FOREIGN KEY (message_id) REFERENCES messages(id);
Назначение полей:
message_id - привязка к конкретному сообщению
file_name - имя файла
mime_type - тип данных: "application/zip", "application/pdf", "image/png" и т.д.
file_size - размер файла в байтах
location - расположение файла
СКРИПТЫ
Описание работы: первый скрипт подключается к почтовому серверу, записывает в базу данных UID-ы новых писем, а второй скрипт, который будет рассмотрен позднее, по UID писем закачивает содержимое писем с вложениями и другой информацией.
Скрипт для чтения новых писем (reader.php)
uid;
wr("add message $message_uid");
//создаем запись в таблице messages,
//тем самым поставив сообщение в очередь на загрузку
$sql = "INSERT INTO messages(mailbox_id,uid,create_date,is_ready)
VALUES($mailbox_id,$message_uid,now(),0)";
mysql_query($sql) or die(mysql_error());
}
if($message_uid != - 1){
wr("last message uid = $message_uid");
//если появились новые сообщения,
//то сохраняем UID последнего сообщения
$sql = "UPDATE mailboxes
SET last_message_uid = $message_uid
WHERE id = $mailbox_id";
mysql_query($sql) or die(mysql_error());
}else{
//нет новых сообщений
wr("no new messages");
}
}
mysql_query("COMMIT");//завершаем транзакцию
//закрываем IMAP-поток
imap_close($mail);
}
?>
 Далее откроется главное окно:
Далее откроется главное окно:
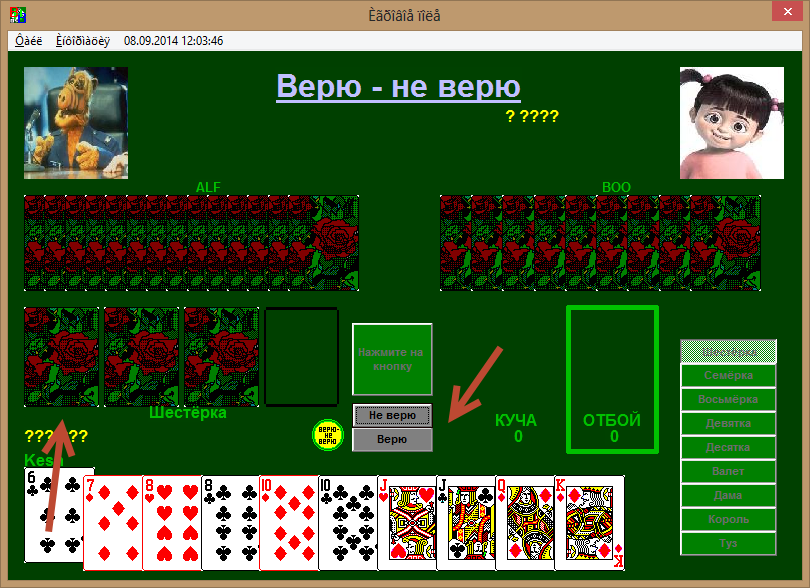 На рисунке изображена ситуация, когда ход дошел до вас, и вы можете либо доложить карты, либо попытать угадать обманул ли вас предыдущий игрок.
Выкладываю также исходный код. Ценности он, может, ни какой и не представляет, но все же...
Скачать исходный код
На рисунке изображена ситуация, когда ход дошел до вас, и вы можете либо доложить карты, либо попытать угадать обманул ли вас предыдущий игрок.
Выкладываю также исходный код. Ценности он, может, ни какой и не представляет, но все же...
Скачать исходный код