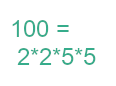Устанавливать ESPnet будем на Ubuntu 22.04, где по умолчанию Python версии 3.10.12. Скачиваем espnet из репозитория https://github.com/espnet/espnet/ или отсюда Установите библиотеки Откройте директорию espnet/tools с установочными скриптами Установите miniconda Установите виртульную среду Python Настройте Python Соберите и установить ESPnet c PyTorch версии 1.12.1 Выполнить скрипт activate_python.sh